Gradient Descent Into Madness
Augment your workflow with AI and let agentic AI agentically augment the AI workflow until the workflow itself becomes AI which makes working at AI-native agentic scale feasible. Coding is solved! Vulnerability research is cooked! 10x! 100x! Workflow! AI!
I hate hype and I hate hyperbole. It puts me immediately into a wary state and makes it highly unlikely that I’ll engage with a topic.
Artificial Intelligence is a prime example. I don’t dislike the technical side. In hindsight, quite the contrary. But I just cannot get over the marketing hype, the promises and superlatives. Last week I went to an electronic store and every advertisement banner featured “AI” prominently, no matter if the product in question was a phone or a washing machine.
But slowly, over time, more credible and interesting claims emerged. My turning point was the recent development in information security capabilities.
I finally felt the need for a deep-dive in order to form my own educated opinions.
These are merely my cleaned-up notes of a month’s worth of wading through AI. Because it’s literally impossible to keep up with all aspects of the field, this first post might still provide some use for people who have been bystanders at best for the last couple of years. I’ll provide many resources as pointers for further investigation of the different topics.
tl;dr: This post is for people like me that typed some questions into a Web UI and generated some funny pictures in 2023 and are now wondering why AI can buy domains, find 271 vulnerabilities in Firefox and is the topic of the pope’s first encyclical letter.
Small History of Artificial Intelligence
The term Artificial Intelligence (AI) was coined in the 1950s by John McCarthy.1
People these days are not talking about that AI, though. They talk about large language models.
Small History of Large Language Models
A Large Language Model (LLM) is a neural network trained on enormous amounts of data in order to get good at natural language processing (NLP) tasks like text generation. We’re only talking about LLMs in this article.
A neural network is a model that takes inputs, runs them through a network of interconnected neurons and produces outputs. It gets trained on known data with the goal of being able to produce meaningful output for unknown data.
Machine learning is the part of AI that builds these models from data.
Deep learning turns this up to eleven by creating really big neural networks with many layers.
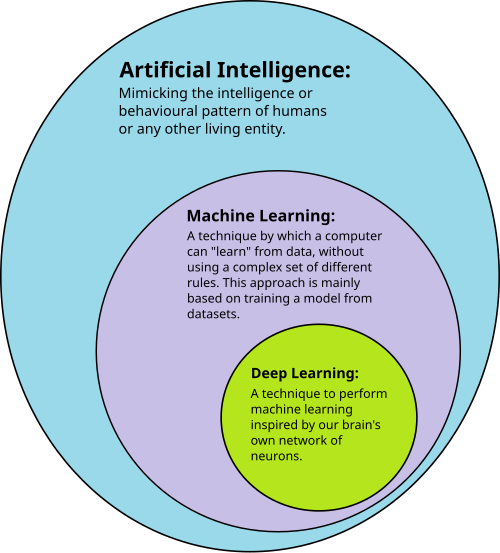
Figure 1: By Original file: Avimanyu786SVG version: Tukijaaliwa - File:AI-ML-DL.png, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=90131352
LLMs emerged from advances in deep learning over the last couple of decades:
- Training is ideally suited for GPUs2
- Algorithmic and architectural improvements (e.g. the transformer architecture, see below)
- BIG DATA
How much data? Let’s look at an example:
Common Crawl is a free repository of web crawl data. The latest main archive at the time of writing (CC-MAIN-2026-17) is a whopping 85 TB in size. Modern models were trained on a lot more data than this, which fuels the ongoing copyright debate and numerous lawsuits.3
The release of the 2017 paper “Attention Is All You Need”4 and its introduction of the transformer architecture often gets mentioned as a watershed moment for machine learning. In comparison to previous architectures, the self-attention mechanism allows processing the complete input (more precisely: all input tokens) at once instead of sequentially (like in Recurrent Neural Networks), which parallelizes well on GPUs and makes training at today’s enormous scale practical. All of the major modern LLMs are based on this architecture, which even made its way into OpenAI’s model naming scheme, where the “GPT” stands for “generative pre-trained transformer”.
Speaking of which, 2018 saw the release of the first “GPT” model by OpenAI, which demonstrated the now-standard way of training a model: Pre-train a transformer on huge amounts of text, then fine-tune the result for specific tasks.
A year later, in February 2019, “GPT-2” was partially released. At first, it was deemed too dangerous to be fully released publicly5, which seems comical today. It didn’t deter Anthropic from pulling a similar stunt with their “Mythos” model, though.6
The release of “ChatGPT” (using the GPT-3.5 model) in November 2022 probably had the most impact on the general public’s perception, which quickly turned into one of the most used applications ever.7 Its cultural impact cannot be overstated, as it sparked numerous discussions about the future of education, white collar jobs and copyright among many other topics.
Today there are a couple of big players, mainly OpenAI, Anthropic, Google (all US), DeepSeek (China) and Mistral AI (France) among others. These companies offer access to many different models, some of which are called frontier models (like Anthropic’s Opus 4.8) because of their size and capabilities. Most of the time, the models are closed, meaning we only get API-level access to them. Contrast that to open models (like Google’s Gemma 4), which can be used locally on our machines.
While the core LLMs see constant improvement, the main difference to the ancient ChatGPT days is mostly the stuff that’s piled on top: Tool usage / function calling, Retrieval-Augmented Generation (RAG), AI-native code editors and most importantly agents.
But let’s take a step back and define what a model even is.
What is a Large Language Model?
A large language model is a type of neural network that accepts text8 as input, which gets turned into a collection of numbers, and produces an output. Models consist of weights and biases (typically floats) that can be tuned to change the output. The weights connect neurons across layers of the neural network and their values represent the strength of the connections.
Tuning these parameters to produce the correct output for a given input is known as training. This process involves algorithms like gradient descent and backpropagation to adapt the weights to get the model closer to producing the desired output.
Figure 2: Floats. Everywhere.
Models are measured by their number of parameters, e.g. the largest GPT-2 model has 1.5 billion parameters, which mainly consist of weights. Newer models have much more parameters.
An LLM’s only job is to predict the next token (usually subword chunks) in a sequence. Because its training data consists of vast amounts of text, there’s no need to curate a list of desired (labeled) outputs. The correct next token is always known (it’s simply the continuation of the input sequence) and can be used as a reference for the model’s output. This is known as self-supervised learning and is a very efficient method of training on large amounts of data.
Overall, we could say that an LLM is a really complicated text prediction function trained on roughly the whole Internet in a computationally expensive process.
Quite anticlimactic when phrased that way, right?
Another important concept is a model’s context window or context length, which is the number of tokens a model can “see” at once. Because a model generates the output one token at a time and each new token is produced by feeding everything so far back into the model, the context window affects both input and output. In other words: a very long input might leave less room for a response. And very long responses can push against the same ceiling.
A base model is produced after the self-supervised pre-training phase. It captures the statistical structure of natural language, but is not yet suited for any specific task except for text completion.
The next stage is fine-tuning, which steers the model into a desired direction, like being an assistant that can follow instructions. This stage uses a much smaller but higher-quality dataset and often incorporates human feedback.
I’ve… commissioned a little test page where you can test the difference between pre-trained and instruction fine-tuned models right in your browser. Both models come from the SmolLM2 family9.
You can access it here. It’s quite resource hungry and about 250 MB of model data will be downloaded on the first visit (but gets cached for subsequent visits).
Here’s a sample run for the prompt “What is the capital of Germany?”

Figure 3: Pre-trained vs fine-tuned SmolLM2 response for ‘What’s the capital of Germany?’
And here’s one for “Write a poem about the sun.”

Figure 4: Pre-trained vs fine-tuned SmolLM2 response for ‘Write a poem about the sun.’
Even taking the very small model size of 135 million parameters into account (which weakens the results across the board), we can still clearly see that the fine-tuned model responds a lot better to our instructions, whereas the base model only generates text.
Neither the architecture nor the parameters of most frontier models are available. When they are available, we call it an open model. Openness can vary from releasing just the weights to releasing all the accompanying code, documentation and dataset descriptions (“open weights” vs “open source”).
Open models allow custom fine-tuning for specific tasks, which can be achieved on a budget (at least compared to the cost of training a base model). Hugging Face is the most prominent place where people share (fine-tuned) models and datasets.
From RAGs to Riches
LLMs have a clear training cutoff, which means their knowledge about the world is frozen in time. While this is fine for many tasks, it can become a liability when newer information needs to be taken into account for an accurate answer. Moreover, giving a model access to external knowledge at query time was shown to “make it ‘hallucinate’ less with generations that are more factual, and offer more control and interpretability”.10
“External Knowledge” refers to some kind of document index, usually a vector database:
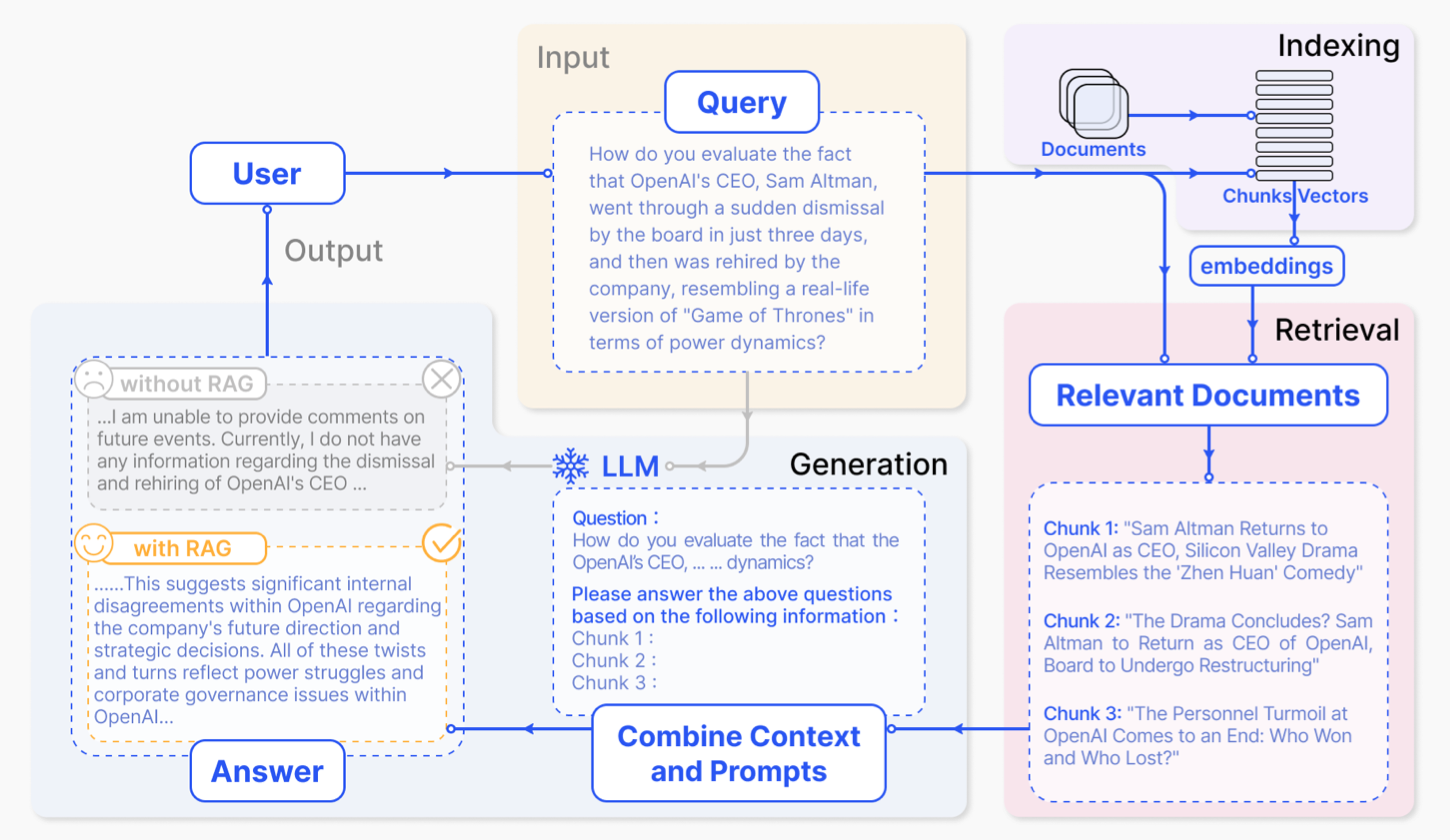
Figure 5: RAG process (source: https://arxiv.org/pdf/2312.10997)
The user’s query gets embedded into a vector and the document index gets searched for relevant passages, which subsequently get added to the context to produce more accurate results. As mentioned, the upsides are less hallucinations and the ability to correctly cite the sources (among other things).
An index could be a mostly static corpus of domain-specific documents (think internal documentation of a large company) or simply the Internet if up to date information is needed.
It goes without saying that the quality of the response depends heavily on the quality of the retrieved document chunks. Additionally, retrieving external documents also expands the attack surface, as we’ll learn in the next post.
Agents
Agents probably mark the biggest shift in LLM usage. We went from posting text into a webpage to having GitHub Copilot-style tab completion in our IDEs or even special “AI-enabled” IDEs such as Cursor and Windsurf to agents that can work on tasks autonomously for a prolonged time.
The poster child is “Claude Code” by Anthropic, which had its public release in May 2025.
Claude Code is an agentic coding tool that lives in your terminal, understands your codebase, and helps you code faster by executing routine tasks, explaining complex code, and handling git workflows - all through natural language commands.
- https://github.com/anthropics/claude-code
In other words, agents are LLMs with tools in a loop. Example tools are file manipulation (read, write, edit) or access to a shell.11
Agents receive their initial prompt and work from there. The two examples in the introduction, buying domains and finding vulnerabilities, are agents doing their agentic thing. Here’s a diagram of an agentic loop:

Figure 6: Claude Code’s agentic loop (source: https://code.claude.com/docs/en/agent-sdk/agent-loop#the-loop-at-a-glance)
Other popular agents are Pi, Open Code and OpenAI’s Codex.
Agents are all the rage these days. People claim they make developers [insert number between 10 and 100] times more productive. At the same time, it appears that all the agentic productivity is causing GitHub outages.12
Not only are agents pushing a lot more code, they also create lots of pull requests. The aforementioned Pi project even auto-closes all issues or PRs from new contributors.13
All this craze led people to create “tokenmaxxing” leaderboards, which incentivizes employees to spend as much money on AI as possible.
Because remember:
If that $500,000 engineer did not consume at least $250,000 worth of tokens, I am going to be deeply alarmed.
- Jensen Huang, Nvidia CEO
It’s easy to dismiss agents outright because of the hyperbole-bullshit-machinery, but they’re definitely worth a closer look. Many credible people started to experiment with them for security research purposes, which led to a flood of new vulnerabilities in the last months.14
Conclusion
There you have it! An incomplete, lopsided introduction to the current AI craze! When it’s working, it feels like magic. The NLP part is genuinely incredible. All the technical aspects are fascinating and definitely worth a look (see Resources). Agents - today - can create software and find vulnerabilities in large projects. They can even create exploits.
At the same time, there are many problems:
- the outputs of the models are stochastic by nature, meaning two exact same prompts can lead to different responses
- models will happily hallucinate answers and they’ll sound more convincing than I ever could
- models can develop biases depending on the data they’ve been trained on
- at the moment, the most capable frontier models are predominantly owned by private US-based companies
- worst of all: the Steam Machine got delayed because of the insane RAM prices
Additionally, we haven’t even talked about security, which is of course the most interesting topic of all and will be the subject of the next post.
While everybody is rushing towards viable products and tons of money gets spent/burned15, we could probably do worse than to keep Daniel Jalkut’s take in mind:
My take on AI is, essentially, everybody who’s against it is too against it and everybody who’s for it is too for it.
Resources
Articles and Books
Graydon Hoare - “LLM Time”
https://graydon2.dreamwidth.org/322732.html
Frederik Braun - “Multiple things can be true at the same time”
https://frederikbraun.de/feels-and-llms.html
Thomas Ptacek - “Vulnerability Research Is Cooked”
https://sockpuppet.org/blog/2026/03/30/vulnerability-research-is-cooked/
Simon Willison’s Weblog (a great aggregator)
https://simonwillison.net
Nicholas Carlini (now Anthropic) - “How I Use ‘AI’”
https://nicholas.carlini.com/writing/2024/how-i-use-ai.html
Sebastian Raschka - “Build a Large Language Model (From Scratch)”
https://www.manning.com/books/build-a-large-language-model-from-scratch
Ronald T. Kneusel - “How AI Works”
https://nostarch.com/how-ai-works
Numa Dhamani and Maggie Engler - “Introduction to Generative AI, Second Edition”
https://www.manning.com/books/introduction-to-generative-ai-second-edition
Videos and Podcasts
Casey Muratori and Demetri Spanos - “Wading Through AI”
https://www.computerenhance.com/s/wading-through-ai
Andrej Karpathy - “Deep Dive into LLMs like ChatGPT”
https://www.youtube.com/watch?v=7xTGNNLPyMI
Andrej Karpathy - “Neural Networks: Zero to Hero” (Youtube Playlist)
https://www.youtube.com/playlist?list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ
[un]prompted AI security conference videos
https://www.youtube.com/@un_prompted
Brendan Bycroft - “LLM Visualization”
https://bbycroft.net/llm
https://web.archive.org/web/20070826230310/http://www-formal.stanford.edu/jmc/history/dartmouth/dartmouth.html ↩︎
http://www.robotics.stanford.edu/~ang/papers/icml09-LargeScaleUnsupervisedDeepLearningGPU.pdf ↩︎
https://copyrightalliance.org/participating-bartz-v-anthropic-settlement/ ↩︎
Granted, it did find the Firefox bugs mentioned in the introduction so this time caution might be appropriate. ↩︎
https://finance.yahoo.com/news/chatgpt-sets-record-fastest-growing-190911828.html ↩︎
Ignoring multimodal models for now. ↩︎
Actually those are all the tools that the Pi agent ships, see https://pi.dev/docs/latest/quickstart#first-session. ↩︎
https://github.com/earendil-works/pi/blob/main/CONTRIBUTING.md#contribution-gate ↩︎
See Daniel Stenberg (Curl) https://daniel.haxx.se/blog/2026/04/22/ and Chrome 148 release https://chromereleases.googleblog.com/2026/05/stable-channel-update-for-desktop_0877304591.html. Mind you I don’t know how many vulnerabilities were found with AI involvement, but many projects had unprecedented numbers of disclosed vulnerabilities in the last months. ↩︎